I recommend AI: How/Why I Use It in its entirety here are just a couple of my favorite passages:
“As any musician knows intimately, the most interesting part of a new musical technology is its glitches: the inventors of the synthesizer hoped to position it as a replacement for strings or horns, but what we loved is the weird blorps; the amplifier was invented just to make a guitar more audible, but we loved distortion; Autotune et al. were invented to correct bad notes, but we loved crazy space-laser voices.”
“Every day the AIs “improve” their ability to make images (actually, I use one of my go-to AIs because it is hilariously bad). I believe that eventually the uncanniness will be refined away, and AIs will evolve from fascinatingly odd to comprehensively mediocre.”
“Expertise will not be sufficient to make a living…Hacks are in trouble. If somebody is making work that is uninspired, and unindividual, then they can indeed be replaced by a machine that just spits up boring chunks of mid-ness.”
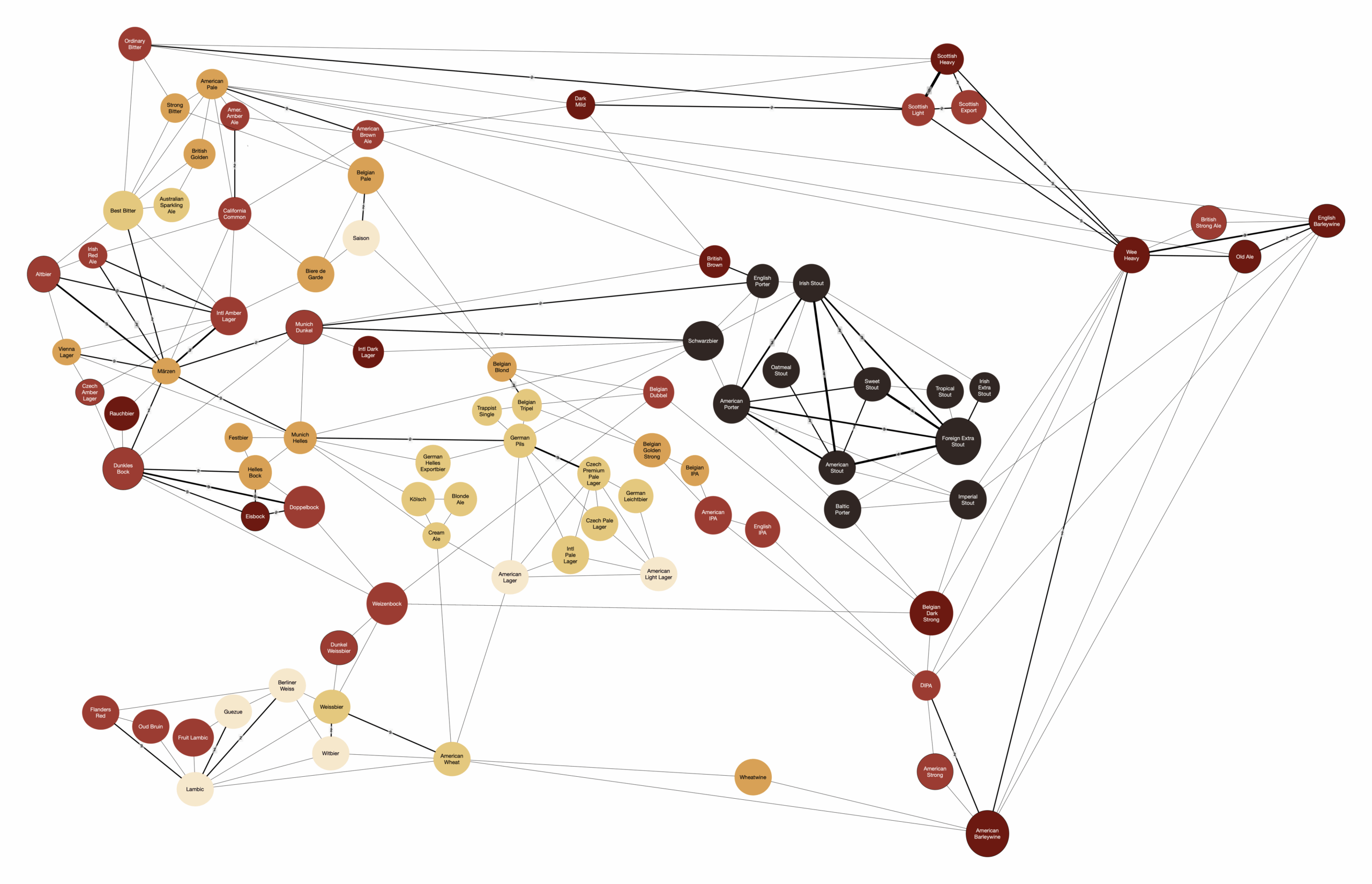
The intention of this graph is to help those studying for the BJCP Written Exam in prioritizing which styles to focus on for the compare/contrast portion.
Generative AI and LLMs continue to provide the least controversial answer to any question I ask them. For my purposes, this makes them little more than a calculator for words, a generator of historical fiction short stories.
As I mentioned two years ago, this doesn’t make LLMs useless, but it does greatly shrink their usefulness – to those places where you want a general idea of the consensus…whether or not it’s correct, accurate, or legal. Just an average doesn’t necessarily represent any individual datapoint.
For, the more training data the generative AI providers shovel into their models, the greater the drift from credibility toward absurdity the generated consensus.
It’s one thing to train the models on all the scientific research. It’s another to train on all the books ever published (copyright issues aside for the moment). It’s quite another to train it on Reddit and Twitter. It’s yet another thing all together to treat all data equal independent of parody, satire, or propaganda.
Again, there are use cases for this (e.g. getting familiar with the basics of a topic in record time), but the moment you expect quality, credibility, or specifics…it collapses like a toy giraffe.
A toy giraffe that, when a person engages with it, can only – collapse.
As a metaphor for new technologies, this toy giraffe’s message is worth considering, “we break when any pressure is applied.”
General purpose LLMs will only get worse the more data they digest. Special purpose LLMs only trained on a specific context, a specific vertical, a rigidly curated & edited set of sources may achieve the level of expert these applications are hyped up to be.
But we may never know they exist because the most valuable use cases – national defense, cybersecurity, fraud detection – will never need (or desire) the visibility the general purpose LLMs require.