
“…Success was never final and failure never fatal” – Budweiser
Finding what's forgotten.
TLDR: My default position is still, “if an LLM is good at it, we probably don’t need it.“
Which means I’m always amused when I hear people talk about how they use LLMs in their work as it inherently betrays the parts of their job they consider tedious. Though, this could also be said for any aspect of work that’s been automated by a machine or software.
Claude: Claude wins on personality, but loses on rate limiting (as I’ve mentioned before), also I’m developing an allergy to Claude’s written voice. If you want a sure fire way to demonstrate you didn’t use an LLM in your writing, make it aggressively short and pointed.
I’ve lost track of how many times I’ve asked Claude a question and all I got back was an excessively long clarifying question then immediately rate-limited. Other times Claude and I can have a more satisfying conversation. I’ve an overall fatigue with Claude’s ever shifting usage thresholds relative to the user experience. I don’t know how many tokens my request is – nor do I have control over how much tokens are burned in the response. The resulting experience is too much like playing slots. Microsoft and Google are better positioned to win the LLM game as they have other revenue sources.
Gemini: I built one app (ACV Outlier) that hits the Gemini API and recently used the Gemini inside Google Maps to maps out a 13mi bike ride – because it was more accessible than remembering how to create custom routes via the UI.
I use Gemini when I:
Boardy: Boardy has given me 3 dozen introductions over the past year or so – as of late it’s about 3 per week. As Boardy’s networks grows, the introductions have improved. As much as Boardy always wants to provide introductions, sometimes I just use it to get a read on the overall market and talk through ideas for new offerings.
VS Code: whatever the default model is seems to work sufficiently well for the work I do and my $10/mn subscription. My default stack is: Rails + SQLite + (Tailwind + DaisyUI). One of my favorite things to do is ask the model “how do we make this more The Rails Way”, and it spits back a bunch of ways to clean up the code it just wrote.
ChatGPT: not at all.
A head of biz dev at B2B finance marketplace startup called me today, and started off with:
“I’ve read your profile. We don’t have a pricing problem. Our pricing is good. We have a customer problem.”
First off, helluva way to jump in. Props.
Second, there’s a list of startup business models I’m inherently skeptical of. Two-sided marketplaces are right close to the top of that list.
My skepticism isn’t that they don’t exist or can’t work. Just that, out of the gate, it’s massively resource intensive just to prove it works, a high volume of people – ready to transact – are needed on both sides.
“The man who chases two rabbits, catches neither.” – Roman proverb
I worked on a couple of these inside the venture studio. One found lots of volume on the supply side but none on the demand side. The other never found enough volume on either side, but was able to execute one single transaction.
In 2011, Lynn Breedlove founded Homobiles, a nonprofit providing safe rides to San Francisco’s LGBT community – drag queens, transgender riders, and the people taxis refused pick up. Donation-based. Breedlove was the driver. Then more people volunteered to drive. Not a marketplace. Neighbors serving neighbors.
Both the co-founder of Sidecar and a former Uber exec credit Homobiles as their inspiration for enabling regular drivers to provide rides in their regular cars. In 2013, after 4 different organizations had proven demand for the model, Travis Kalanick CEO of Uber, who had publicly stated that regular drivers in regular cars wouldn’t work, adopted it.
Homobiles wasn’t trying to build a two-sided marketplace. They were trying to get each other home safely.
The two-sided marketplace model came later. Years later.
Which leads me to my two-sided marketplace litmus test: Can any transacting party be on both sides of the transaction?
An Uber driver could be a Uber passenger. An eBay buyer could be an eBay seller.
If it doesn’t pass this test, it’s not a marketplace, it’s something else entirely. Thankfully that something probably simpler and easier to execute at founder-scale.
Back when two-sided marketplaces were super hot, I attended a Business Model Canvas workshop. Alex Osterwalder was demonstrating how to diagram a two-sided marketplace. His recommendation: one canvas, two highlighters, a different color for each side of the marketplace.
Double the customer segments, double the value props, more double the complexity. Same single page. Iterating on either side meant navigating around the other. Like two people in a trenchcoat. Even the example at the front of the room was difficult to follow.
It’s like the BMC itself was whispering “just pick a one side”.
Yesterday, I talked with two founders envisioning a two-sided marketplace for handyman work in apartment complexes.
Already, you can tell from that description, it’s not a two-sided marketplace. It’s a facilities maintenance service for multi-family housing more focused on getting the work done than it is with who does the work. Even better! Amazing.
The founders are general contractors, selling directly to property managers. No platform. No marketplace. Just learning who the best buyers are, quoting the work, booking the contract, assigning parts of the job to themselves and parts to their crew, and capturing the full margin on every job in the process.
This. Not because it’s elegant. Not because it’s scalable. Because it produces real demand information, real revenue, today. We don’t need to worry about volume or matching algorithms. Just customer sales.
Admittedly, this is what the head of biz dev at the top of the article meant by “a customer problem.” To their credit, they are shifting to a direct sales model.
I don’t know how many finance people the head of biz dev has in their stable. What I know is this biz dev person needs to sell 2,000 hours to pay for themselves. That’s 1.5 finance people fully-booked for a year. That’s not really a marketplace, it’s a typical small business accounting firm.
Which might be even better.
Sometime around October 1991, I missed my all time favorite band, Too Much Joy, playing at First Ave. I was as a teenager living on a dirt road in rural Wisconsin with no ability to get to Minneapolis on a school night. Thankfully the Minneapolis alt rock FM station, KJ104, broadcast it live. With relief and delight, I recorded onto cassette tape from my bedroom.
Despite the recording being awful – a live band, in a venue not set up for recording, broadcast on FM, then saved on a cassette tape recorder I bought from K-Mart – I was cherished it and would blast the concert recording over the wind noise of a third-hand Ford Ranger. I’m sure to anyone in the passenger seat the entire thing was unintelligible distortions. I don’t remember any of the set list other than Drum Machine, as it was the strangest song I had heard to that point, but I felt like I captured magic in a bottle every time I hit play.
Last month, I found a case of a couple hundred CD-ROMs containing “backups” of my university work, early professional work, early programming projects, that time I tried to teach my self a drum machine, and so many other things I had forgotten. I put quotes around “backups” because after 20+ years the majority of the discs could not longer be read. Even the professionally produced ones.

I haven’t thought about deliberating making a backup of any kind in more than 15 years. I trust iCloud does what I pay it to do. So, I was surprised to find generation loss still exists, shifting to something more subtle and therefore more problematic.
I collected 50 odd topics on future For Starters posts from readers like you. I threw them into Claude and got back 8 overall categories with some paraphrasing of the questions I dismissed as normalization. So, I started reorganizing things, re-labeling them, and sending them back to Claude for a second opinion. I ended up with an uninspiring list of bland, corporate words without weight, categories without distinctions. Unsatisfying. But, I just thought I was tired and moved on.
Looking through the original notes today, for the specific person asking a specific question, I was met with the richness, clarity, character, and nuance of all the original questions. All the earlier back and forth with an LLM just provided an increasingly worse response.
This blog post has been a review of The Backrooms. An anti-AI, sci-fi, thriller set in that stereotypical dream trope of finding another room in your apartment where you put everything you wanted to forget, as you’re chased by the darkest, worst remembered, version of yourself.
“If your $200k/year employees spend their time vibe-coding a replacement for a $15/mo Calendly subscription, your business is not going to make it.” – Davide Grieco, Head of Growth, Clay
This morning I talked with a super excited founder, they were walking me through a very comprehensive and sophisticated home-grown application to manage his solo consulting firm: calendar events, to-dos, email drafts, CRM, charts of progress, red-yell0w-green indicators. I’d never seen anything so sophisticated for a 1-person business, or a 10-person business.
Then I looked in the address bar, a local file served out of a Claude Co-work directory.
Of course.
This meant it doesn’t work on his phone. It didn’t appear to connect to his native email, calendar, contacts, or reminders. It only works on this specific machine for as long as he has sufficient Claude tokens. A bit of a reversion in a world of always-on, mobile connectivity.
It was the most elaborate example of actively not learning existing tools I’ve seen since February .
He is currently searching for a software engineer to help deploy it.
Of course.
Now admittedly, I’m guilty of the same crime.
I greatly enjoyed building tablestrength, and ‘brewbook’, and ‘familymap’, they have become my go-to tools for the job I’ve created them for. There are other tried and true solutions to the problems I’m solving with these apps. I didn’t need to create my own, and just to emphasize it, I probably shouldn’t have.
A SaaS sales leader posted this week about running his entire monthly pipeline review through Claude via a Salesforce MCP integration.
No more cludgy UI. No more need to coordinate with his co-workers. Data in seconds. He was delighted, giddy with how much faster the review process will be next month. Not questioning if the monthly review itself was actually valuable – or if there was some other higher leverage activity, or even different frequency, his organization could be focused on, now the data is more accessible.

Early plastic household goods were skinned in woodgrain because manufacturers didn’t yet know what plastic actually was or if consumers would accept it. The first metal joints mimicked carpentry joints. The first iPhone used an excessive number of scarce pixels to recreate a yellow notepad and a wooden magazine rack.
When the microwave came to market, cookbooks encouraged cooking whole chicken in it.
We first dress new capabilities in the clothing we’re familiar with. Then we figure out what the new thing can actually do.
The vibe-coded dashboard still looks important. The monthly pipeline review through Claude still a monthly pipeline review. A email expanded with AI to assert significance from an earlier age.
We’re in the skeuomorphism phase of LLMs. What if the value is, in fact, zero? What if LLMs exposed just how unthoughtful, ineffective, and backwards looking the bulk of our daily activities are?

What if we’re all Jeff Koons bringing weight to emptiness? Creating enormous, plaster sculptures of inflatables and trite ephemera out of some combination of “shoulds” and “we’ve always done” and “how I was trained” and “not my job” for a world slowly dissolving into history.
“…looks like a landing strip.
…a control tower made of bamboo.
…a satellite dish built of mud and straw.
….men light torches and place them alongside the runway. Others use flags to wave landing signals.
They wait.
But the planes never come.” – Dimitris Xygalatas

It all appears significant. Yet, just going through the motions.
“If you couldn’t be bothered to write it, I can’t be bothered to read it.” – Brad Koehn
The cartoon at the top isn’t a joke about LLM’s. It’s a joke about how slowly we let go of yesterday.
Previously: You’re Not Going to Need It.

A thin lit edge of a pale blue dot against vast nothingness.
The same picture Apollo 8 took in 1968.
Updated for 2026.
To remind us, all of us:
Everything and everyone we have ever touched is somewhere on this planet.
Still.

In 1983, Atari buried 14 tons of unsold E.T. cartridges in a New Mexico landfill. In 2014, a documentary crew dug them up and redistributed them;
New Mexico Museum of Space History,
Centre for Computing History in Cambridge, England,
880 auctioned off to individual buyers.

Shipping container knocked off in a storm, now lodged in fissure along the shoreline.
Thousands of Garfield phones washed up on French beaches for the next thirty years.
The ocean continuing to redistribute them.
All the phones are still here, somewhere.

Silas and Margaret met in Pennsylvania.
Silas insisted they move to Des Moines for land and opportunity.
Margaret hated Iowa.
Eventually,
Silas relented.
They moved to Texas.
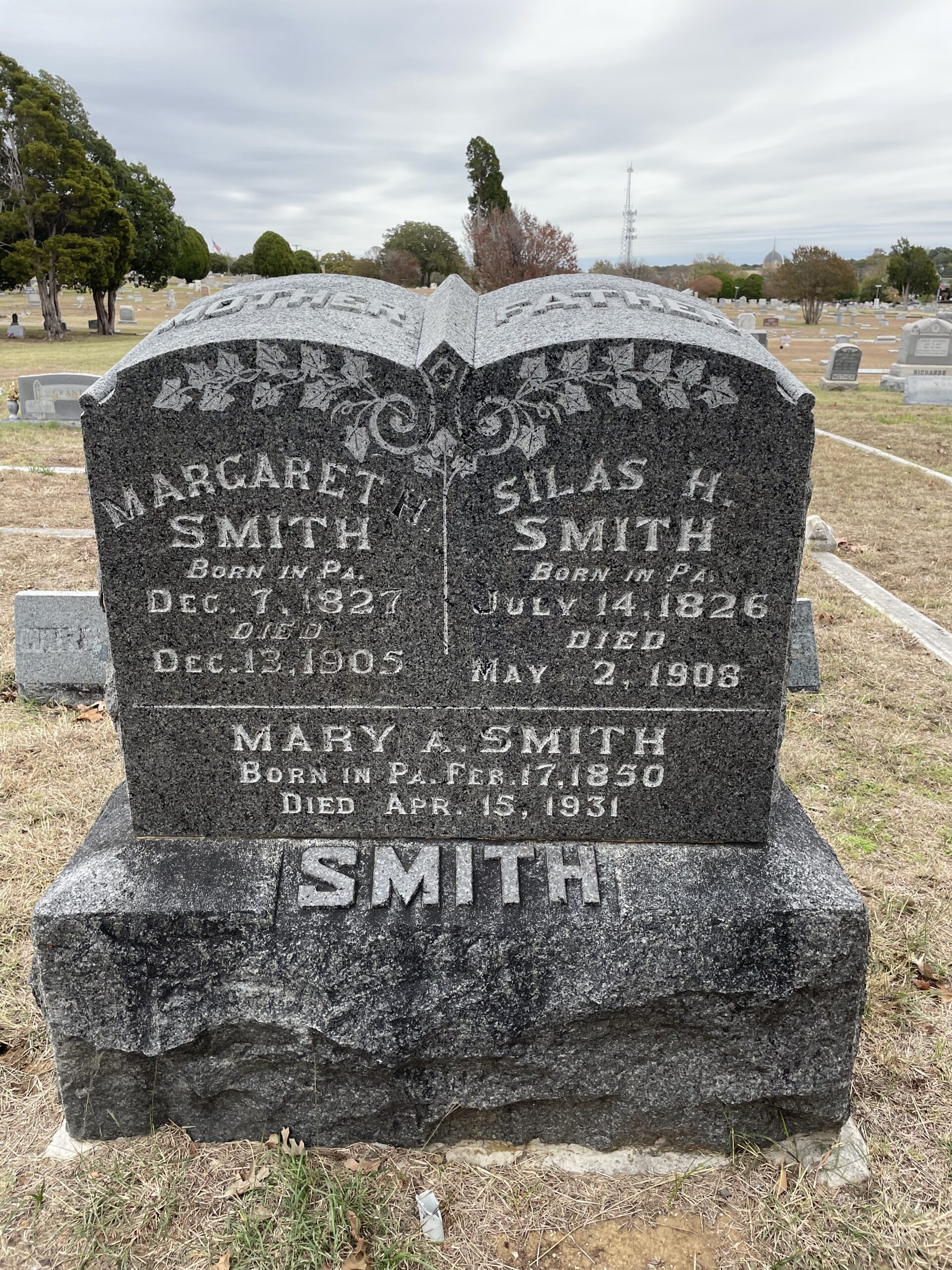
“…there is no hint that help will come from elsewhere to save us from ourselves.” – Carl Sagan
The kids didn’t unload the dishwasher this morning.

